
AI: Replace vocals in a song by using RVC AI
Purpose
I wanted to hear how some of my favorite songs would sound when sung by a different singer, even if the song has never been interpreted by that singer in real life. Without the budget and the connections in the music industry to make such collaborations happen, my only option is to create these songs with the help of RVC AI.
What is RVC AI?
Retrieval-based Voice Conversion (RVC) is a technique that uses a deep neural network to transform the voice of a speaker into another voice. It is based on the VITS model, which is a state-of-the-art end-to-end text-to-speech system. RVC can be used to create realistic and expressive voice conversions with minimal data and computational resources[i].
Project Description
For this project, I wanted to create a song that in nature would sound well when pairing the instrumental portion of the song with the new voice. I also wanted to create something unique and different from most songs being created using this technology. Therefore, I decided to look back into the songs which my grandparents grew up listening to back in the 40-50s and which became classics and have them interpreted by the musicians I grew up listening to.
I chose the Spanish song “Lamento Borincano”, composed by the famous Rafael Hernandez Marin[ii] in 1929[iii], and later interpreted by Daniel Santos[iv]. The song’s tone and theme are melancholic and sad. Daniel Santos’s interpretation sounds mellow and bohemian. That is the main reason why I wanted to listen to the former Menudo and well-recognized singer, musician, and songwriter, Robi Draco Rosa[v], singing this song. In my opinion, his low, mellow, and bohemian voice would go very well with this song, yet his style brings the song to modern days.
Tools
The following tools were used in this project.
Steps
Data Source
Gradio recommends a dataset of around 10 to 50 minutes.
I used 2 full solo albums of the singer with a total duration of roughly 117 minutes.
For the dataset to be useful the source of the voice has to be isolated.
I used the Ultimate Vocal Remover 5 (UVR5), which uses Deep Neural Networks to isolate the vocals from the instrumental portion of any song, to separate the vocals from each track of the songs used as a source.

The options which worked best were the following.
Using Max Specs for Vocals and Instrumental, even though I could’ve used Max Spec only for Vocals since it was the only portion, I needed to build my model.
The models used in UVR5 were:
- MDX-Net: UVR-MDX Net Inst HQ 1 (for instrumental)
- MDX-Net: UVR-MDX NET Main (for vocals)
The GPU Conversion was used to use my computer’s GPU instead of my CPU.
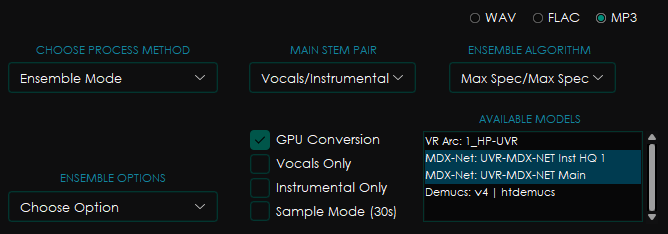
Each track was processed very fast, and the results were surprisingly good.
Note: Gradio also provides the capability to separate the voice from the instrumental portion of the song using UVR5, already integrated with the tool.

Now with all 117 minutes of the vocals isolated I could build my model using Gradio.
Data Preprocessing
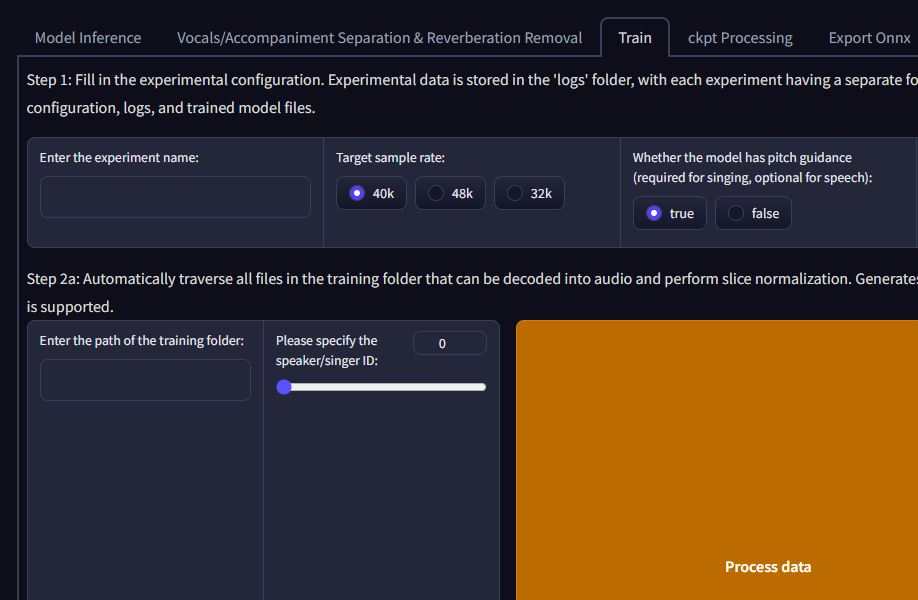
Under the “Train” tab in Gradio the interface is split into three major steps to create the model. I will leave a link below to a YouTube video that explains in detail the steps to follow. The interface looks confusing at first glance, but the steps are easy to follow and not much input is required.
In the first couple of steps, Gradio processes the source dataset and extracts the features. It automatically traverses all files in the training folder that can be decoded into audio and perform slice normalization. Generates 2 wav folders in the experiment directory. Then it uses CPU to extract pitch (if the model has pitch), and GPU to extract features.
Training the Model
In the final step where it trains the model, Gradio makes it extremely easy to do so with a One-click training feature. But this is where I spent most of my time since I had to try multiple times with different settings to make things work.
Challenge
The challenge I kept encountering was that after attempting to train my model and completing the process there was no result. No model was generated. After carefully examining the log in the command prompt window I noticed that there was a “CUDA out of memory” error message somewhere in the prompt. After some research and tweaking my training settings, this problem was solved by reducing the Batch size per GPU from 40 to 20. I did not try to go beyond 20 since 20 managed to train my model quite fast.
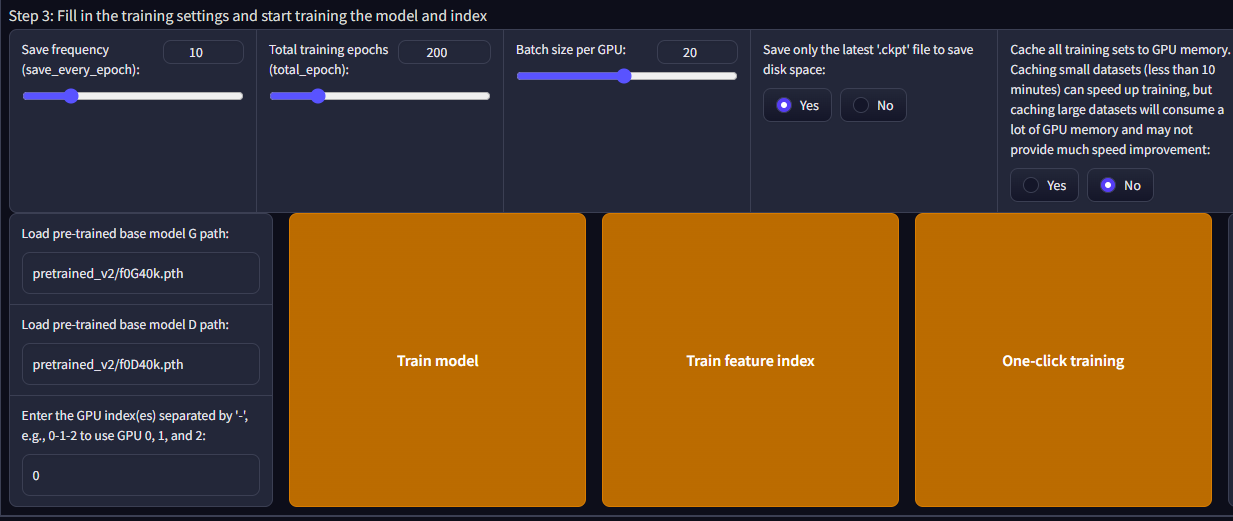
I trained my model to 200 epochs, but it converged earlier, therefore concluding the process.

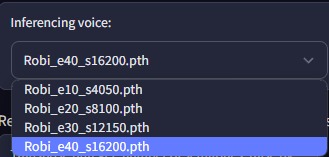
I chose to save my model every 10 epochs, which after conversion gave me 4 models to choose from in intervals of 10 epochs.
Implementation
Now it was time to use my model to replace the existing voice of the interpreter with the desired voice.
Before this was possible, I also had to isolate the vocals from the instruments on my target song, which was done using UVR5.
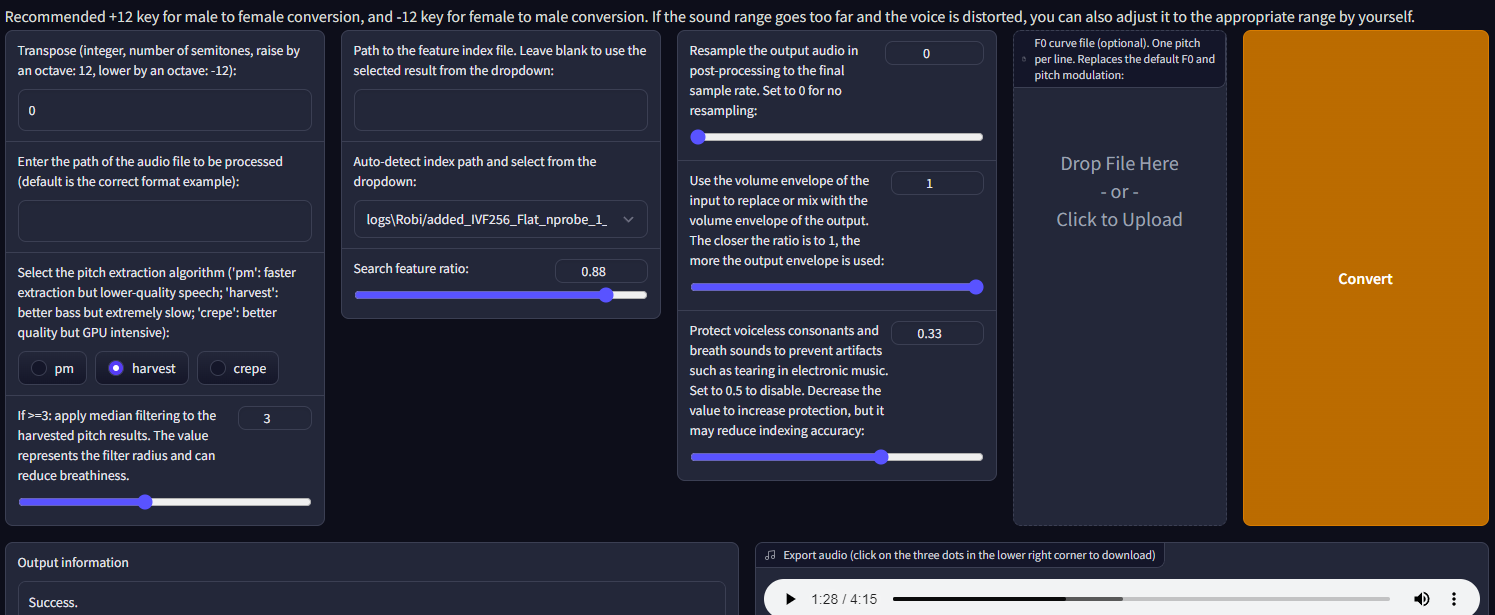
Under “Model Inference” I provided my desired model along with the target audio file to be processed to replace the voice.
After converting the voice, I was able to listen to the result in the tool and download the outcome.
Putting it all together
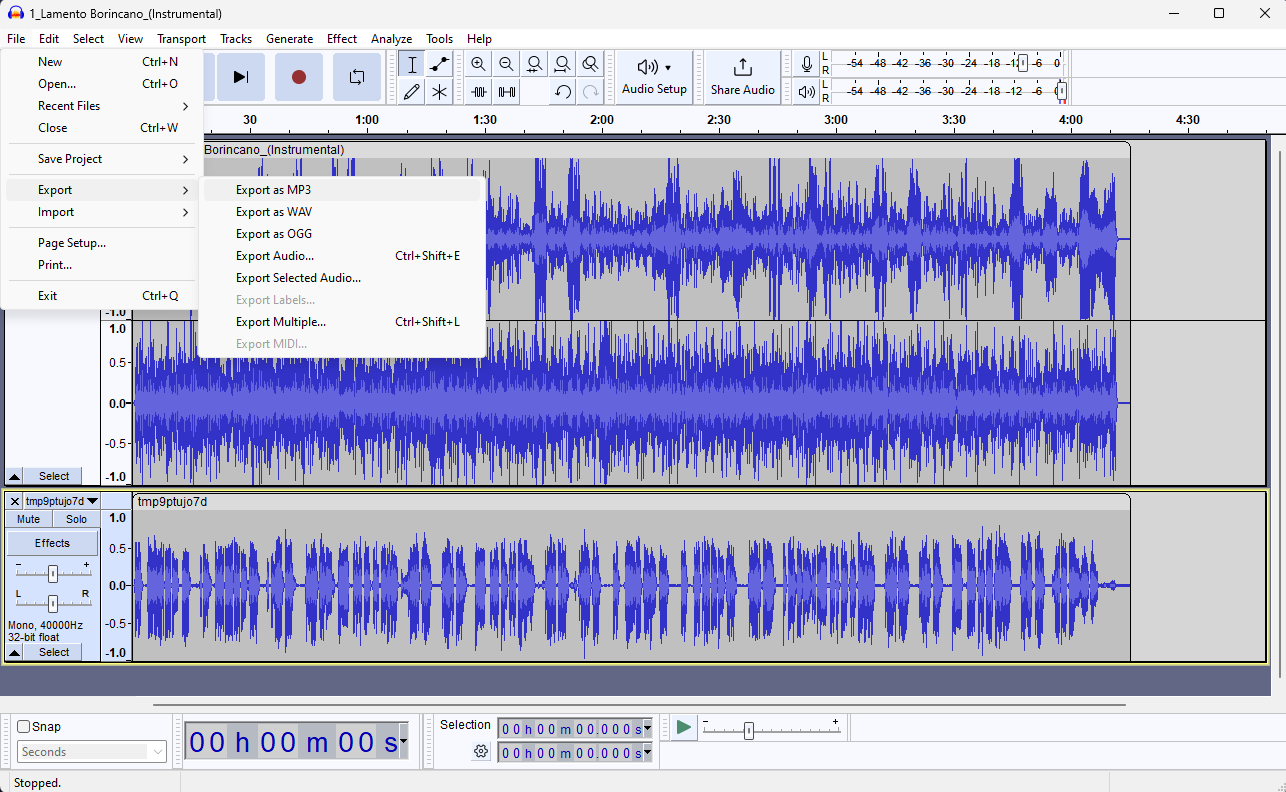
Once satisfied with the result, I had to merge the new vocals with the instrumental portion of the song.
This was easily done using Audacity and exporting both files, vocals and instrumental, in mp3 format.
Outcome
Original
Result
Conclusion
I was very satisfied with the outcome of this project. The voice suits very well the version of the song used in this experiment, and it appears as if the song was sung by Robi Draco Rosa. In the future I will continue to experiment with other singers and different types of music, daring to mix different genres and less compatible musicians.
Reference
RVC – AI Tutorial
Use AI to Clone ANY Voice & Sing ANY Song for FREE | RVC WebUI Tutorial
[i] RVC AI: Retrieval-based Voice Conversion. Retrieved July 19, 2023 from, https://guidady.com/rvc-ai/
[ii] Rafael Hernandez Marin. Retrieved July 19, 2023, from https://en.wikipedia.org/wiki/Rafael_Hern%C3%A1ndez_Mar%C3%ADn
[iii] Lamento Borincano. Retrieved July 19, 2023 from, https://en.wikipedia.org/wiki/Lamento_Borincano
[iv] Daniel Santos (Singer). Retrieved July 19, 2023 from, https://en.wikipedia.org/wiki/Daniel_Santos_(singer)
[v] Draco Rosa. Retrieved July 19, 2023 from, https://en.wikipedia.org/wiki/Draco_Rosa